
x86汇编笔记
基础知识
在x86计算机中,所有数据存储的基本单位都是字节(byte),一个字节有8位。其他的存储单位还有字(word)
dword(双字)
字单元:由两个地址连续的内存单元组成。
高地址内存单元中存放字型数据的高位字节,低地址内存单元中存放字型数据的低位字节。
当我们需要把数据存入段寄存器的时候,8086CPU是不可以直接存的,必须先把数据传入到普通的寄存器里,然后再传到段寄存器里。
1 | mov ax,1000H |
在 x86 汇编语言(Intel 语法)中,[0] 表示一个内存地址。方括号 [] 的作用是内存寻址,可以理解为“访问位于…地址的内容”
物理地址 = 段地址 * 16 + 偏移地址
- [0]:这里的 0 是一个偏移地址 (offset)。方括号告诉处理器,操作的目标不是一个立即数 0,而是一个内存地址。
- 这个偏移地址 0 是相对于**数据段(DS)**的起始位置的。
- 所以,[0] 指的是数据段的第一个字节,即偏移量为 0 的地址。
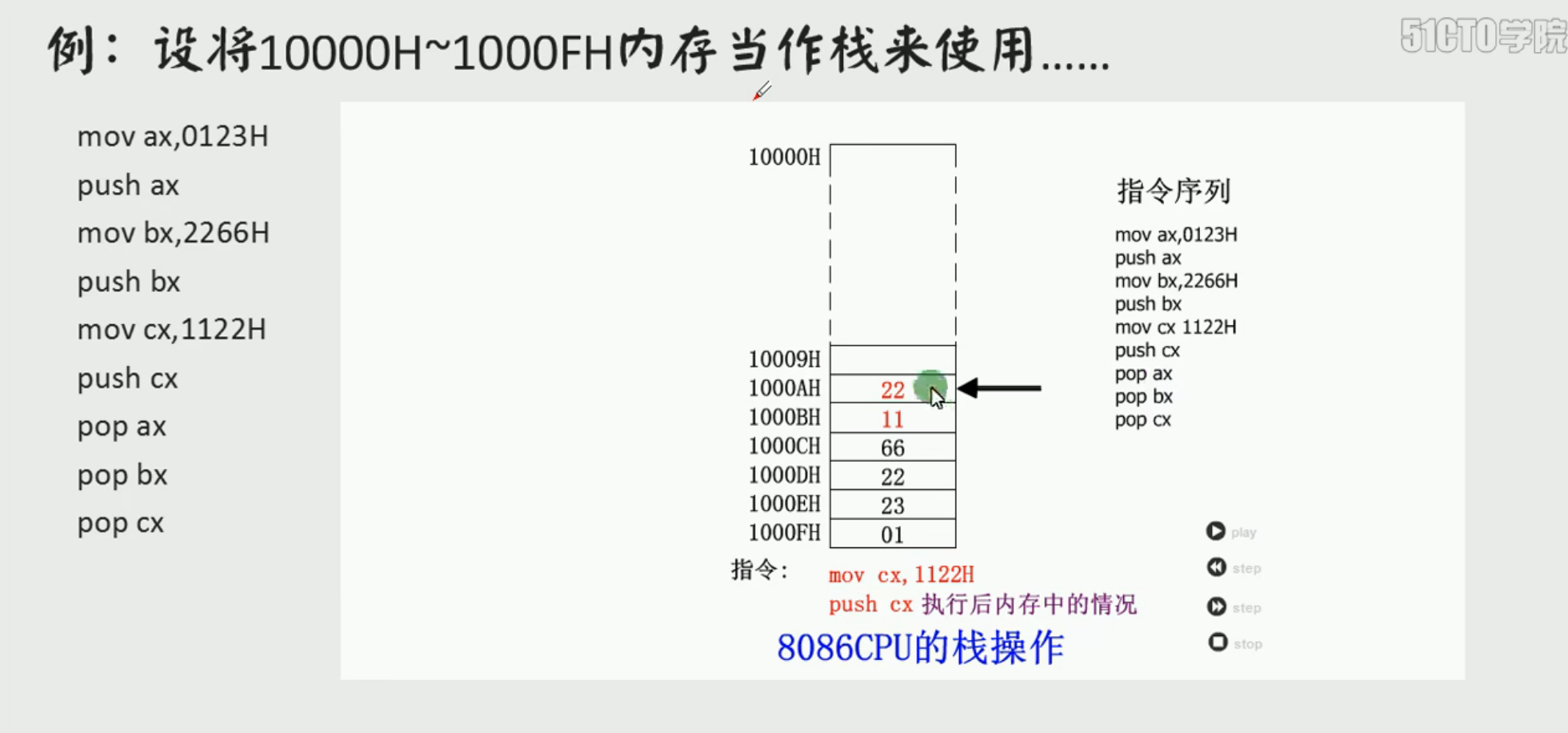
push入栈 比如 push ax把寄存器ax中的数据压入栈中
pop出栈 比如 pop ax表示从栈顶取出数据送入ax中
cs与ip
cs是代码段寄存器,IP是指令指针寄存器
栈顶的段地址存放在SS段寄存器中
栈顶的偏移地址存放在SP寄存器中

重新来看push ax这个代码,ax是16位寄存器,一个字节是8位,所以要留出来2个字节的位置
sp=sp-2,sp一直指向栈顶
pop ax //sp=sp+2
1 | assume cs:codemsg |
[]和()的规定
- []表示一个内存单元
| 指令 | 段地址 | 偏移地址 | 操作单位 |
|---|---|---|---|
| mov ax,[0] | 在DS中 | 在[0]中 | 字 |
| mov al,[0] | 在DS中 | 在[0]中 | 字节 |
| mov ax,[bx] | 在DS中 | 在[bx]中 | 字 |
| mov al,[bx] | 在DS中 | 在[bx]中 | 字节 |
- ()表示一个内存单元或寄存器中的内容
| 描述对象 | 描述方法 | 描述对象 | 描述方法 |
|---|---|---|---|
| ax中的内容为0010H | (ax)=0010H | 2000:1000处的内容为0010H | (21000H)=0010H |
| mov ax,[2]的功能 | (ax)=((ds)*16+2) | mov [2],ax的功能 | (ds*16)+2=(ax) |
| add ax,2 的功能 | (ax)=(ax)+2 | add ax,bx的功能 | (ax)=(ax)+(bx) |
| push ax 的功能 | (sp)=(sp)-2 (ax)=((ss)*16+(sp)) | pop ax 的功能 | (ax)=((ss)*16+(sp)) (sp)=(sp)+2 |
loop指令
1 | assume cs:code |
[!IMPORTANT]
在汇编源程序中,数据不能以字母开头,要在ffff前面加0
段前缀的使用
如何将内存ffff:0ffff:b中的数据拷贝到0:2000:20b中?
初始方案
1 | assume cs:code |
CX 是“计数寄存器”(Count Register),loop 指令会自动检查 CX 的值来决定循环次数。
这段代码稍微有点“低效”,因为它在循环内部频繁地切换 DS 寄存器(先设为 FFFF 读取,再设为 0020 写入)。
- 更优化的写法通常会利用 ES (附加段寄存器)。例如:让 DS 指向源 (FFFF),让 ES 指向目的 (0020),然后直接从 DS:[BX] 复制到 ES:[BX],这样就不需要在循环里一直修改 DS 了。
优化方案
1 | assume cs:code |
AND 和 OR指令
and 是与运算,两个对应的位置相同才是1,不同是0
or是或运算,两个对应的位置不同是1,否则是0
大小写转换
1 | assume cs:codemsg,ds:datasg |
在此基础上,如果两个字符串的大小相等。可以用[bx+5]的这种格式,在每一次循环里,能够把两个字符串的同一位置的字符统一做出修改
[bx+idata]的偏移地址更加灵活
SI和DI寄存器
SI:source index,源变址寄存器
DI:destination index,目标变址寄存器
[!CAUTION]
区别:SI和DI是不可以分成两个8位寄存器来使用的
而AX,BX,CX,DX基础寄存器可以分为某L,某H两个8位寄存器来使用的
mov ax,[bx+si+idata]
不同的寻址方式
[idata]用一个常量来表示地址,可以直接定位一个内存单元
[bx]用一个变量来表示内存地址,可用于间接定位一个内存单元
[bx+idata]用一个变量和常量来表示内存地址,可以在一个起始地址的基础上用变量间接定位一个内存单元
[bx+si]用两个变量表示地址
[bx+si+idata]用两个变量和一个常量来表示地址
在1.5的案例中,只使用了一个循环计数器。我们开阔一下思维方式,如果要进行多重循环呢?可以使用什么方式呢?
答案是运用嵌套循环,但是和c,python等高级语言的用法不一样。在多重循环里,一个寄存器的值在外层循环已经确定后,在放在内层循环,如果再修改就错了啊,但是我们又知道循环计数器就是cx控制,如果我们把cx的数值先存到dx寄存器里,那是不是就行了呢?我们知道,计算机只有很少的寄存器,14个。在运行一个很复杂的程序时,函数就有很多个。把cx的数值先存到dx寄存器里是绝对不行的。
那怎么办?前面所提到的栈,刚刚好可以解决我们的这个问题,我们只要合理设置栈的大小,防止被pwn,然后运用push压入数据,pop取出数据,就可以完美实现我们想要的多重循环。
1 | .8086 ; 指定16位8086指令集(DOS环境兼容) |
指令要处理的数据有多长
在8086cpu的指令中,可以处理两种尺寸的数据,byte和word。所以在机器指令中要指明,指令进行的是字操作还是字节操作
通过寄存器的类型来判断
如果是16位寄存器,比如说下面的这段代码
1 | mov ax,1 |
标志性的ax寄存器,说明存储的是字word
如果是8位寄存器,比如说下面的这段代码
1 | mov al,1 |
标志性的al和bl,说明存储的是字节byte
div指令
div是除法指令
被除数:默认放在AX或AX和DX中,如果除数为8位,被除数则为16位,默认在AX中存放。如果除数为16位,被除数为32位,在DX和AX中存放,DX存放高16位
除数:有8位和16位两种,在一个reg或者内存单元里
结果:如果除数为8位,则AL存储除法操作的商,AH存储除法操作的余数;如果除数为16位,则AX存储除法操作的商。DX存储除法操作的余数。
例1:用100001/100
100001明显大于65536,说明不能只能AX寄存器存储,必须要用DX和AX联合存储,这么一来就是32位寄存器。而100又
小于255,可以使用8位寄存器,但是32位作被除数,那除数必须是16位的。因为要分别为dx和ax赋10001的高16位值和低16位值
1 | mov dx,1 |
例2:用1001/100
被除数1001可以用AX寄存器存储,100可以用8位寄存器存储,也就是进行8位的除法
1 | mov ax,1001 |
伪指令dd
前面我们用db和dw定义字节型数据和字型数据。dd是用来定义双字类型的数据。
1 | daatmsg segment |
dup指令
dup是一个操作符,用来进行数据的重复
1 | db 3 dup (0) ;表示有3个字节,然后都是0,相当于db 0,0,0 |
操作符offset
offest的功能是取得标号的偏移地址。
1 | assume cs:codesg |
在上面的程序中,offest操作符取得了标号start和s的偏移地址0和3
start位于最开始,那偏移地址就是0,这个毫无疑问。对相当于mov ax,3肯定有疑惑,
为什么这里就变成3了呢?
怀着疑问,问了豆包,得到了答案
answer
start后面的指令是mov ax, offset start,这条指令的机器码长度是 3 字节**(mov ax, 立即数的指令格式:操作码B8+ 2 字节立即数,共 3 字节)。**
JMP跳转指令
根据位移进行转移的jmp指令
jmp short 标号(转到标号处执行指令)IP=IP+8位位移,8位位移的范围是-127-128,用补码表示
jmp near ptr IP=IP+16位位移
jmp far ptr实现的是段间转移 CS=标号所在段的段地址 IP=标号在段中的偏移地址
jmp word ptr 内存单元地址(段内转移)
jmp dword ptr 内存单元地址(段间转移)
jcxz指令
用c语言来解释这个指令
if((cx)==0) jmp short 标号
loop指令
(cx)--
if((cx)!=0) jmp short 标号
call指令
函数指令,跳转到函数的地址,执行函数。
call word ptr 内存单元地址
mul指令
mul是乘法指令,无符号数乘法
1 | mul <操作数> |
两个数相乘,要么都是8位,要么都是16位,如果是8位,一个放在al里,一个放在reg(寄存器里)或者内存字节单元中。如果是16位,一个默认在ax中,另一个放在16位的reg或者内存字单元中。
如果是8位乘法,结果默认放在AX中;如果是16位乘法,结果高位默认在DX中存放,低位在AX中存放。
操作数
**寄存器操作数:**可以使用通用寄存器(如R0、R1等)或特殊寄存器(如EAX、EBX等)来存储乘法结果。
**内存操作数:*可以使用内存地址来存储乘法结果。这种情况下,需要使用一个间接寻址操作符(如)来指定内存地址。
**立即数操作数:**可以在指令中使用立即数(即常数)作为操作数。这种情况下,乘法结果将直接存储在指令指定的寄存器中。
eg.mul byte ptr ds:[0] ; AX=AL×(ds*16+0)
eg2.mul word ptr [bx+si+8]; AX
imul
imul也是乘法指令,但是它是有符号数的乘法
标志寄存器
标志寄存器是14个寄存器里的最后一个,叫做flag寄存器
flag寄存器是用来存放数据的,和其他寄存器不一样。而flag寄存器是按位起作用的,也就是说,它的每一位都有专门的含义。
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OF | DF | IF | TF | SF | ZF | AF | PF | CF |
ZF标志
flag的第六位是ZF,零标志位。执行相关指令后,其结果是否为0。如果结果为0,那么zf=1。如果不如0,zf=0
PF标志
flag的第二位是PF,奇偶标志位。执行指令结束后,其结果的所有bit位中的1的个数是否是偶数。如果1的个数为偶数,pf=1,如果为奇数,那么pf=0。
SF标志
flag的第七位是SF,符号标志位。执行指令结束后,结果如果是负的,sf=1,如果非负,sf=0。
CF标志
flag的第零位是CF,进位标志位。记录了运算结果的最高有效位向更高位的进位值,或者从更高位的借位值。对无符号的运算是有意义的
OF标志
flag的第十一位是OF,溢出标志位,对有符号数运算有意义的标志位
adc指令
adc是带进位加法指令,它利用了CF位上记录的进位值。
用法:adc ax,bx ;表示ax=ax+bx+CF
例子:
1 | mov ax,2 ;ax=2 |
inc指令
inc是加法指令,给寄存器的值+1
用法:inc ax ;表示给ax的值+1
sub指令
和add指令相反,是减法。
用法:sub ax,bx ;表示ax=ax-bx
sbb指令
sbb是带借位减法指令,它利用了CF位上记录的借位值
用法:sbb ax,bx ;ax=ax-bx-CF
cmp指令
cmp是比较指令,cmp的功能相当于减法指令,只是不保存结果,但是会对标志寄存器产生影响,然后其他指令通过判断标志寄存器的值,从而判断是否该执行指令。
控制转移指令
| 操作符 | 功能 | 示例 |
|---|---|---|
| jmp | 无条件跳转 | jmp 0x00401000 |
| call | 调用子程序 | call 0x00401000 |
| ret | 返回到调用点 | ret |
| je / jz | 如果相等(Zero flag置位)跳转 | je 0x00401020 |
| jne / jnz | 如果不等(Zero flag未置位)跳转 | jne 0x00401020 |
| jg | 如果大于跳转 | jg 0x00401020 |
| jl | 如果小于跳转 | jl 0x00401020 |
| jge | 如果大于等于跳转 | jge 0x00401020 |
| jle | 如果小于等于跳转 | jle 0x00401020 |
| loop | 循环跳转 | loop 0x00401020 |
| int | 调用中断 | int 0x80 |
| iret | 从中断返回 | iret |
| ja | 无符号数大于则跳转(Above) | ja 0x00401020 |
DF标志和串传送指令
DF方向标志位,可以控制si,di的增减
DF=0,每次操作后si,di递增
DF=1,每次操作后si,di递减
cld和std指令控制df的值
cld:将标志寄存器的DF位设为0(clear)
std:将标志寄存器的DF位设为1(setup)
lea指令
lea 目的寄存器, 源内存寻址方式
把 “内存地址的偏移量” 加载到寄存器
rep指令
根据cx的值,重复执行后面的指令
eg. rep movsb
rep movsb 指令详解
rep movsb 是一条在汇编语言中用于高效进行内存块(字符串)复制的复合指令。它结合了rep前缀和movsb指令,实现了硬件级别的循环复制,比手动编写的循环效率要高得多。
1. 核心作用
作用: 批量复制字符串或内存块数据。
2. 指令构成
这条复合指令由两部分组成:
- rep: 是**“Repeat”(重复)**的缩写,一个指令前缀。它的作用是根据计数器寄存器 ECX 的值,重复执行其后面的字符串操作指令,直到 ECX 变为0。
- movsb: 是**“Move String Byte”(移动字符串字节)**的缩写。它执行一次单独的字节复制操作。
因此,rep movsb 的含义就是:“重复执行‘移动一个字节’的操作,直到完成指定数量的字节”。
3. 使用方法与相关寄存器
在使用 rep movsb 之前,必须正确设置三个关键的寄存器:
- ECX (Counter Register): 计数器。用于指定总共要复制的字节数。rep前缀每执行一次 movsb,就会自动将 ECX 的值减 1。
- ESI (Source Index): 源地址指针。用于指向要复制的数据的起始内存地址。
- EDI (Destination Index): 目标地址指针。用于指向数据要被复制到的目标的起始内存地址。
4. 代码示例
codeAssembly
1 | ; 假设我们有 source、destination 两个内存地址 |
5. 执行流程(正向复制为例)
- 先执行
cld确保 DF=0(默认正向); - 给
ECX赋值要复制的字节数,ESI赋值源地址,EDI赋值目的地址; - 执行rep movsb,CPU 会循环执行以下操作,直到ECX=0:
- 把
[ESI]地址的 1 个字节数据复制到[EDI]; ESI += 1,EDI += 1(因 DF=0);ECX -= 1;
- 把
- 循环结束,完成批量字节复制。
方向标志位 (Direction Flag) 的重要性
- cld (Clear Direction Flag): 将 DF 设置为0。这使得 ESI 和 EDI 在每次操作后递增,实现从前往后(从低地址到高地址)的复制。这是最常用的模式。
- std (Set Direction Flag): 将 DF 设置为1。这使得 ESI 和 EDI 在每次操作后递减,实现从后往前(从高地址到低地址)的复制。这种模式在处理有重叠的内存区域时非常有用。
在绝大多数情况下,执行内存复制前,都应该先用 cld 指令来确保复制方向是正确的。
6. 其他相关指令
movsb 只是字符串移动指令家族的一员,还有处理不同数据大小的变体:
- movsw: 移动一个字 (Word),即2个字节。ECX 应该设置为要移动的字数。ESI 和 EDI 每次增/减2。
- movsd: 移动一个双字 (Double Word),即4个字节。ECX 应该设置为要移动的双字数。ESI 和 EDI 每次增/减4。
- movsq (仅限x64): 移动一个四字 (Quad Word),即8个字节。RCX 应该设置为要移动的四字数。RSI 和 RDI 每次增/减8。
移位指令
1.SHL
shl 寄存器, 移位位数
逻辑左移,先将一个寄存器里的数的最高位存入CF标志寄存器。再将其他的各个数往左移动几位。移动多少位要看参数写的什么
最低位用0补充
eg.
1 | mov ax,100000011b 转化为16进制 00000001 11111011 |
结果是00000011 11110110
2.SHR
shr 寄存器,移位位数
逻辑右移,先将一个寄存器里的数的最低位存入CF标志寄存器,再将其他的各个数往右移动几位。移动多少位要看参数写的什么
最低位用0补充
单步中断
TF陷阱标志
当用于调试时单步方式操作。TF=1,会触发陷阱,中断发生。TF=0,cpu正常运行。
IF中断标志
当IF=1的时候,允许cpu响应可屏蔽中断请求。当IF=0时,关闭中断




