
x86 汇编学习笔记
x86 汇编学习笔记
这篇笔记主要围绕 8086 / 16 位 x86 汇编 展开。相比高级语言,汇编更接近机器执行过程,很多“理所当然”的行为都需要你手动控制。
学习汇编时,建议始终抓住三件事:
- 数据放在哪里
- 指令到底对什么对象操作
- 执行后哪些寄存器和标志位发生了变化
只要这三件事想清楚,很多看起来复杂的代码就会变得直观。
一、基础存储单位
在 8086 中,最基本的存储单位是 字节(byte),一个字节等于 8 位。
常见数据单位:
| 名称 | 大小 | 说明 |
|---|---|---|
| byte | 8 位 | 一个字节 |
| word | 16 位 | 两个字节 |
| dword | 32 位 | 四个字节 |
8086 是 16 位 CPU,因此很多指令天然以 word 为核心单位。
大端与小端
x86 采用 小端存储(Little Endian)。
例如一个字 1234H 存入内存时:
- 低地址存
34H - 高地址存
12H
这点在调试内存时非常重要。
二、寄存器总览
8086 中最常见的是以下寄存器。
1. 通用寄存器
| 寄存器 | 常见用途 |
|---|---|
AX |
累加器,很多算术指令默认使用 |
BX |
基址寄存器,常参与寻址 |
CX |
计数寄存器,常配合 loop |
DX |
数据寄存器,常配合乘除法 |
这些 16 位寄存器还可以拆成两个 8 位寄存器:
AX->AH和ALBX->BH和BLCX->CH和CLDX->DH和DL
2. 段寄存器
| 寄存器 | 含义 |
|---|---|
CS |
代码段寄存器 |
DS |
数据段寄存器 |
SS |
栈段寄存器 |
ES |
附加段寄存器 |
3. 偏移寄存器和指针寄存器
| 寄存器 | 含义 |
|---|---|
IP |
指令指针,配合 CS 使用 |
SP |
栈顶偏移地址 |
BP |
基址指针,常用于访问栈内数据 |
SI |
源变址寄存器 |
DI |
目的变址寄存器 |
SI和DI不能像AX一样拆成高低 8 位使用。
三、段地址与物理地址
8086 采用 段地址:偏移地址 的方式访问内存。
物理地址计算公式:
1 | 物理地址 = 段地址 * 16 + 偏移地址 |
例如:
1 | DS = 1000H |
那么 DS:BX 对应的物理地址就是:
1 | 1000H * 10H + 0002H = 10002H |
这也是为什么段寄存器里的值通常看起来像“内存块的起点”。
四、为什么不能直接把立即数送入段寄存器
8086 不支持下面这种写法:
1 | mov ds,1000h |
必须借助通用寄存器中转:
1 | mov ax,1000h |
原因很简单:在 8086 指令编码规则里,段寄存器不能直接接收立即数。
五、内存访问与方括号 []
在 Intel 语法中,[] 表示访问内存。
例如:
1 | mov ax,1000h |
这里的 [0] 不是数字 0,而是表示访问 DS:0 这个内存单元。
可以理解为:
- 方括号里放的是地址信息
- 方括号外才是要读写的数据
常见例子
1 | mov ax,[0] |
它们的区别在于:
- 访问的数据大小不同
- 地址来源不同
| 指令 | 地址来源 | 操作大小 |
|---|---|---|
mov ax,[0] |
DS:0 |
word |
mov al,[0] |
DS:0 |
byte |
mov ax,[bx] |
DS:BX |
word |
mov al,[bx] |
DS:BX |
byte |
六、`()`` 的含义
汇编教材里常会用 (ax)、(bx) 这样的记法。它不是实际代码,而是一种描述方式。
例如:
(ax)=0010H表示 AX 中的内容是0010H(ax)=(ax)+2表示 AX 的值加 2(ss)*16+(sp)表示栈顶物理地址
这是帮助理解指令效果的“数学表达”,不是可以直接写进汇编器的语法。
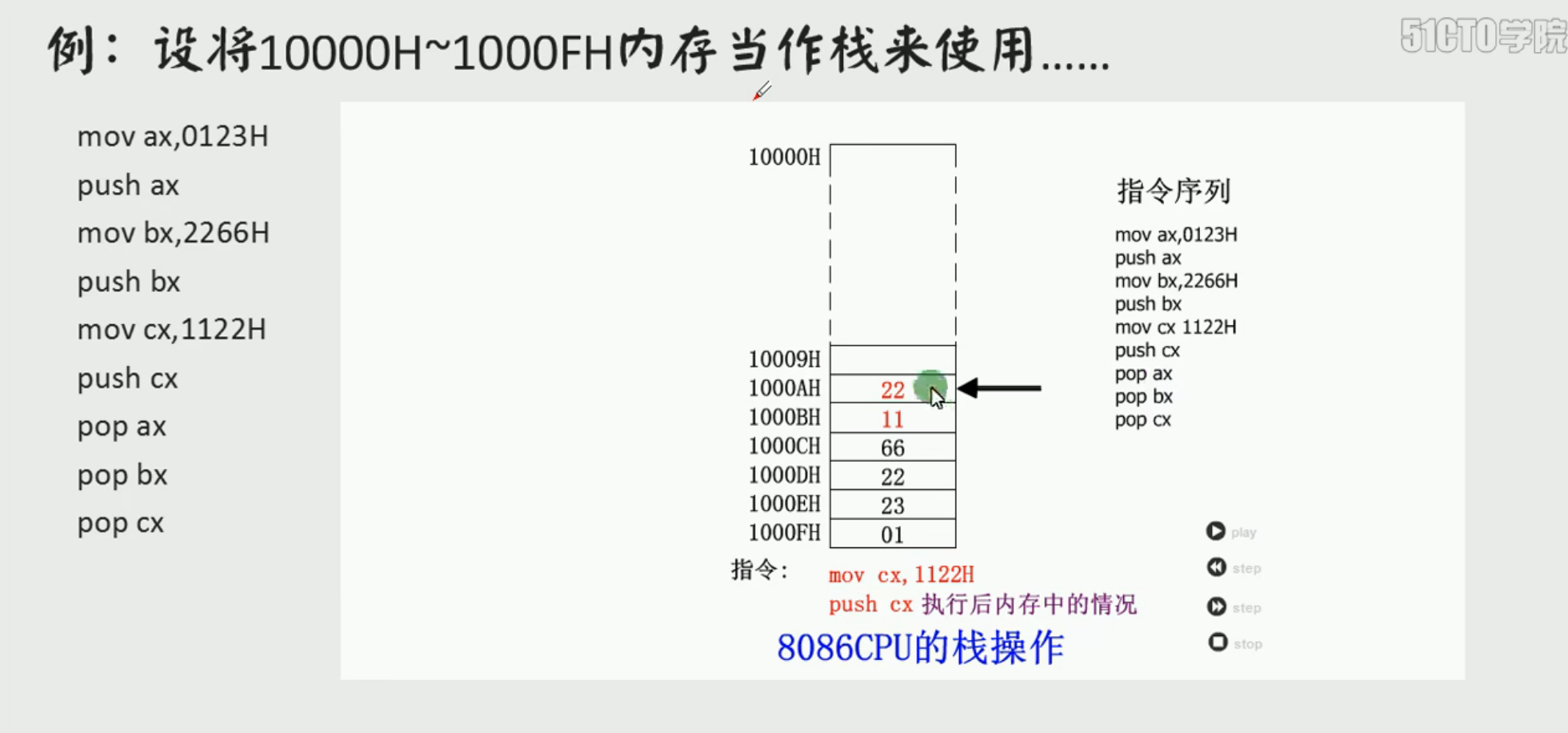
七、栈、SS 和 SP
栈是一种 后进先出(LIFO) 的数据结构。
8086 中:
SS保存栈段地址SP保存栈顶偏移地址
push 和 pop
1 | push ax |
执行逻辑:
push ax:SP = SP - 2,再把AX的值压入栈顶pop ax:先取出SS:SP处的数据送入AX,再SP = SP + 2
原因是 8086 中 AX 是 16 位寄存器,一次压栈/出栈处理一个字,也就是 2 个字节。
八、CS 与 IP
程序执行时,CPU 默认从 CS:IP 指向的位置取指令。
CS:代码段寄存器IP:下一条要执行的指令偏移地址
也就是说:
1 | 当前执行位置 = CS:IP |
如果把栈理解成“数据的出入口”,那么 CS:IP 就是“代码的执行位置”。

九、一个最简单的汇编程序
1 | assume cs:codesg |
这段程序做了什么:
AX = 0123HBX = 0456HAX = AX + BXAX = AX + AXint 21h返回 DOS
这里 mov ax,4c00h + int 21h 是 DOS 环境下最常见的退出方式。
十、loop 指令
loop 是 8086 中非常经典的循环指令,它默认使用 CX。
逻辑可以理解为:
1 | (cx) = (cx) - 1 |
示例:
1 | assume cs:code |
说明:
CX初始值为 11- 每次循环执行
add ax,ax loop s会先把CX减 1,再判断是否继续跳回s
[!IMPORTANT]
loop只能使用CX作为计数器,这是它的固定规则。
十一、段前缀与更高效的复制思路
问题:如何把 FFFF:0000 ~ FFFF:000B 的 12 个字节复制到 0020:0000 ~ 0020:000B?
低效写法
1 | assume cs:code |
这个写法的问题是:在循环内部反复修改 DS,效率低且不优雅。
更合理的写法
1 | assume cs:code |
这里的思路更清楚:
DS固定指向源数据ES固定指向目标区域- 循环里只做读写,不反复切段
十二、与 OR 的常见用途
and
and 是按位与运算:
- 两位都为 1,结果才是 1
- 只要有一位为 0,结果就是 0
or
or 是按位或运算:
- 只要有一位为 1,结果就是 1
- 两位都为 0,结果才是 0
用于大小写转换
ASCII 中英文字母的大小写只差一个 bit,所以可以利用按位操作:
and 11011111b:常用于把小写转大写or 00100000b:常用于把大写转小写
示例:
1 | assume cs:codesg,ds:datasg |
十三、SI 和 DI
SI:Source Index,源变址寄存器DI:Destination Index,目标变址寄存器
它们在字符串处理和复杂寻址中非常常见。
常见寻址形式:
1 | mov ax,[bx+si+idata] |
常见寻址方式总结
| 寻址形式 | 含义 |
|---|---|
[idata] |
用常量地址访问内存 |
[bx] |
用寄存器内容作为偏移地址 |
[bx+idata] |
基址 + 常量偏移 |
[bx+si] |
两个寄存器共同确定偏移 |
[bx+si+idata] |
基址 + 变址 + 偏移 |
掌握寻址方式,是读懂汇编代码的关键之一。
十四、多重循环与栈保存计数器
很多初学者会遇到一个问题:loop 默认使用 CX,那多重循环怎么办?
一个常见思路是:
- 外层循环使用
CX - 进入内层前先
push cx - 内层结束后再
pop cx
示例:
1 | .8086 |
这段代码的重点不是“背下来”,而是理解:
- 栈不仅能存数据
- 也常用来临时保存寄存器现场
十五、指令处理的数据长度
8086 的很多指令要么处理 byte,要么处理 word。
判断方法通常有两类:
- 通过寄存器类型判断
- 通过
byte ptr/word ptr明确指定
例如:
1 | mov ax,1 |
这里的 ax、bx 都是 16 位寄存器,因此处理的是 word。
再看:
1 | mov al,1 |
这里的 al、bl 都是 8 位寄存器,因此处理的是 byte。
十六、div 指令
div 是无符号除法指令。
基本规则
- 如果除数是 8 位,默认被除数在
AX - 如果除数是 16 位,默认被除数在
DX:AX
结果保存位置
- 8 位除法:商在
AL,余数在AH - 16 位除法:商在
AX,余数在DX
例 1:100001 / 100
因为 100001 超过了 16 位范围,所以被除数要放在 DX:AX 中:
1 | mov dx,1 |
例 2:1001 / 100
1 | mov ax,1001 |
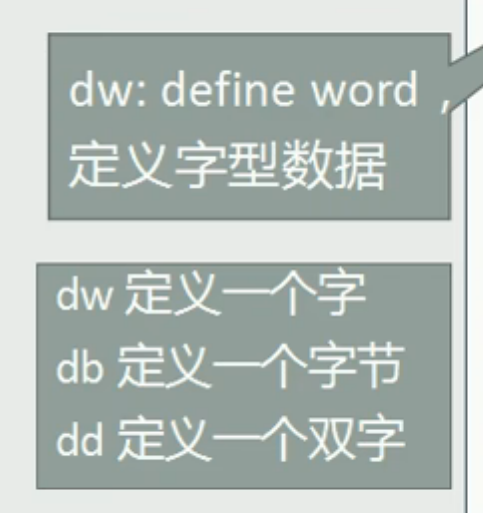
十七、伪指令 db、dw、dd
这些不是 CPU 真正执行的指令,而是告诉汇编器如何定义数据。
1 | datasg segment |
含义:
db:定义字节数据dw:定义字数据dd:定义双字数据
十八、dup 操作符
dup 用来定义重复数据。
1 | db 3 dup (0) |
等价理解:
1 | db 0,0,0 |
这在初始化数组、缓冲区、栈空间时非常有用。
十九、offset 操作符
offset 的作用是取标号的偏移地址。
1 | assume cs:codesg |
如果 start 在段开头,那么 offset start 就是 0。
offset 本质上是让汇编器在编译阶段,直接把标号的偏移值填进指令里。
二十、跳转指令
1. jmp
jmp 是无条件跳转。
常见形式:
jmp short 标号jmp near ptr 标号jmp far ptr 标号jmp word ptr 内存单元jmp dword ptr 内存单元
大致区别:
short:短跳转,范围较小near:段内跳转far:段间跳转,会同时修改CS和IP
2. jcxz
逻辑可以理解为:
1 | 如果 (cx) == 0,则跳转 |
3. loop
逻辑可以理解为:
1 | (cx)-- |
4. call
call 用于调用子程序,执行时会先保存返回地址。
常见流程:
call跳转到子程序- 子程序执行完后用
ret返回
二十一、mul 和 imul
mul
mul 是无符号乘法。
规则:
- 8 位乘法:默认使用
AL - 16 位乘法:默认使用
AX
结果位置:
- 8 位乘法结果在
AX - 16 位乘法结果高位在
DX,低位在AX
例如:
1 | mul bl |
imul
imul 是有符号乘法,规则和 mul 类似,只是它把参与运算的数据当作有符号数。
二十二、标志寄存器
标志寄存器 flag 用于记录运算结果的状态。
| 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OF | DF | IF | TF | SF | ZF | AF | PF | CF |
常见标志位
CF:进位标志,常用于无符号数运算PF:奇偶标志AF:辅助进位标志ZF:零标志,结果为 0 时置 1SF:符号标志,结果为负时置 1TF:陷阱标志,用于单步调试IF:中断允许标志DF:方向标志,控制字符串指令方向OF:溢出标志,常用于有符号数运算
一个重点区分
CF对无符号运算更有意义OF对有符号运算更有意义
二十三、adc、sub、sbb、cmp
1. adc
带进位加法:
1 | adc ax,bx |
逻辑:
1 | ax = ax + bx + CF |
2. sub
普通减法:
1 | sub ax,bx |
3. sbb
带借位减法:
1 | sbb ax,bx |
逻辑:
1 | ax = ax - bx - CF |
4. cmp
cmp 本质上像执行了一次减法,但不保存结果,只更新标志位。
所以很多条件跳转其实都依赖 cmp 之后的 flag 状态。
示例:
1 | mov ax,2 |
这里 sub bx,ax 会影响 CF,后面的 adc 会把这个进位一并算进去。
二十四、控制转移指令速查
| 指令 | 含义 | 说明 |
|---|---|---|
jmp |
无条件跳转 | 直接转移执行流 |
call |
调用子程序 | 保存返回地址 |
ret |
返回 | 回到调用点 |
je / jz |
相等或结果为 0 时跳转 | 看 ZF |
jne / jnz |
不相等时跳转 | 看 ZF |
jg |
大于时跳转 | 有符号比较 |
jl |
小于时跳转 | 有符号比较 |
ja |
无符号大于时跳转 | 看 CF 和 ZF |
jge |
大于等于时跳转 | 有符号比较 |
jle |
小于等于时跳转 | 有符号比较 |
loop |
循环跳转 | 默认使用 CX |
int |
调用中断 | 交给系统服务 |
iret |
中断返回 | 从中断现场恢复 |
二十五、DF 与字符串指令
方向标志 DF 控制字符串指令中 SI、DI 的移动方向:
DF = 0:每次操作后递增DF = 1:每次操作后递减
相关指令:
1 | cld |
含义:
cld:清除方向标志,设置为 0std:设置方向标志为 1
二十六、lea 指令
lea 的作用不是取内存内容,而是 把有效地址本身装入寄存器。
1 | lea ax,[bx+si+8] |
上面这条指令的意思不是“取地址里的值”,而是把 [bx+si+8] 这个地址表达式计算后的偏移值放进 AX。
二十七、rep movsb 详解
rep movsb 是字符串处理里的高频组合。
可以理解为:
movsb:复制一个字节rep:重复执行,次数由CX决定
常见使用方式:
1 | mov cx,length |
执行流程:
- 从
DS:SI取一个字节 - 写到
ES:DI - 若
DF=0,则SI++、DI++ CX--- 若
CX != 0,继续执行
相关字符串指令还有:
movsb:搬运一个字节movsw:搬运一个字movsd:搬运一个双字
在 8086 语境里最常见的是
movsb和movsw。
二十八、移位指令 shl 与 shr
1. shl
逻辑左移:
1 | shl ax,1 |
特点:
- 高位移出进入
CF - 低位补 0
- 在很多场景下可近似理解为乘 2
2. shr
逻辑右移:
1 | shr ax,1 |
特点:
- 低位移出进入
CF - 高位补 0
- 在很多场景下可近似理解为除 2
示例:
1 | mov ax,0000000111111011b |
二十九、单步中断相关标志
1. TF
TF 是陷阱标志。
TF = 1:CPU 进入单步执行模式TF = 0:CPU 正常连续执行
它主要用于调试器逐条跟踪程序。
2. IF
IF 是中断允许标志。
IF = 1:允许响应可屏蔽中断IF = 0:禁止响应可屏蔽中断
三十、学习汇编时的建议
汇编不适合“只看不练”,因为很多理解都依赖你自己去跟寄存器变化。
建议的学习顺序:
- 先熟悉寄存器和数据单位
- 再掌握段地址、偏移地址和内存访问
- 然后学习栈、循环和寻址方式
- 最后再整理字符串指令、标志寄存器和控制转移
做题或调试时,最实用的方法是反复问自己三个问题:
- 这条指令读的是谁
- 写的是谁
- 会改哪些寄存器和标志位
三十一、总结
x86 汇编的难点,不在于语法本身,而在于它把高级语言隐藏掉的细节都摊开给你看了。
当你真正理解了这些内容:
- 段地址和偏移地址如何配合
- 栈为什么能保存现场
loop为什么只认CXcmp为什么不保存结果却仍然重要rep movsb为什么本质上是“硬件循环复制”
那你再去看反汇编、逆向分析或者操作系统底层内容,就会轻松很多。


